LLM(大規模言語モデル)とはなに?仕組みや種類・生成AIとの違い|活用事例や課題をわかりやすく解説

INDEX
- LLM(大規模言語モデル)とはなに?
- LLM(大規模言語モデル)の意味
- LLM(大規模言語モデル)の仕組み
- LLMを動かすための事前準備
- 事前準備を行った後の調整
- LLM(大規模言語モデル)を用いるメリット
- 言語処理が高精度になる
- 文脈を理解するようになる
- LLM(大規模言語モデル)の種類
- GPT系
- PaLM系
- OpenCALM
- LLM(大規模言語モデル)と生成AIとの違い
- LLM(大規模言語モデル)の活用事例
- 検索エンジン
- AIとの対話
- LLM(大規模言語モデル)の課題
- ハルシネーションの存在
- プロンプトインジェクションの存在
- 言語データの枯渇による大規模化への限界点
- まとめ
- さらに、今注目を集める生成AIリスキリングの第一歩を。生成AIパスポートとは?
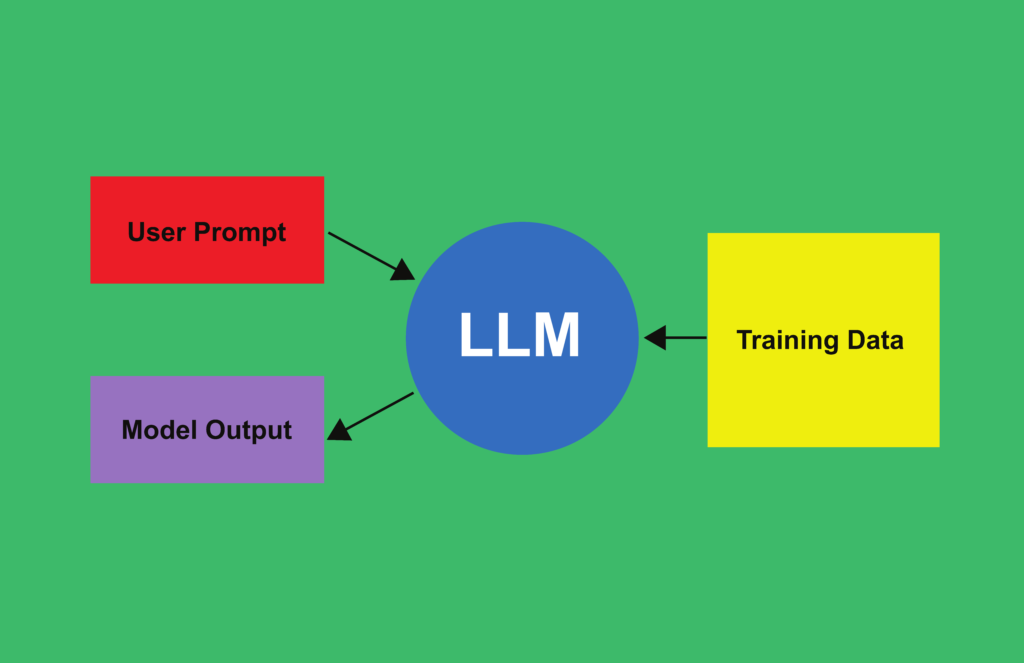
皆さんはLLMをご存じですか?LLMは大量の言葉を学び、AIが人間と同じような感覚で言葉を紡ぎだせるようにした言語モデルを指します。AIが人間のように自然な言葉遣いで文章が作れるのか、注目が集まっています。
本記事ではLLM(大規模言語モデル)とは何か、その意味や仕組み、メリットなどを中心に解説していきます。

LLM(大規模言語モデル)とはなに?

そもそもLLMとはどういうもので、どんな意味があるものなのか、LLMの基本的な解説を行っていきます。
LLM(大規模言語モデル)の意味
LLMはLarge Language Modelsの略称で、日本語で大規模言語モデルとつけられています。ここで用いられている大規模の意味合いですが、一般的に用いられてきた言語モデルよりもデータ量などを大きく増やして用いられたモデルを意味します。
そもそも言語モデルとは、自然な文章となるよう、不自然ではない単語の並び方に高い確率を、不自然な並び方には低い確率を割り当てて、より自然な文章を目指していくというものです。LLMではより自然な文章を目指すべく、活用するデータを大幅に増やしていき、精度を高めていきました。
LLM(大規模言語モデル)の仕組み

LLMを実際に動かすには、事前の準備が必要になり、そのあとで調整をかけていきます。ここでは事前の準備と調整の2つに分けて仕組みをご紹介します。
LLMを動かすための事前準備
LLMを動かすにはまずデータの存在が重要となります。大規模言語モデルとあって、用意するデータの量は相当です。例えば、ChatGPTにもつながるGPT-3というLLMの場合、3000億語の学習を行っているとされています。3000億語は図書館にある本の何十倍以上にも匹敵するもので、まさに桁違いです。
以前は本だけのデータを用いられていましたが、Wikipediaなどのテキストも使って学習が行われるようになっています。たくさんの情報を学習させることで自然な受け答えができるようになります。ですので、いかに事前準備、事前学習を行わせるかがポイントとなるのです。
事前準備を行った後の調整

たくさんの言葉を覚えさせる事前学習、事前準備を終えると、質問を行うなどのタスクを行う際に思ったような結果が出るような調整をかけていきます。この調整作業では、言語の最小単位であるトークンを活用し、それぞれのトークンが持つ文脈を理解していきます。
このトークンをエンコードを用いて数値化していき、この情報を用いて新しい文章を作り出すデコードと呼ばれる作業を繰り返します。エンコードとデコードを繰り返す中で自然な文章が作られていき、微調整を重ね、LLMの精度を高めていきます。
LLM(大規模言語モデル)を用いるメリット
LLMを用いるメリットにはどんなものがあるのか、主なメリットをまとめました。
言語処理が高精度になる
大規模言語モデルではたくさんのデータを学習し、より精度が高いために、チャットボットなどの言語処理がより高精度なものになっていきます。例えば、翻訳作業でも自然な言葉で翻訳ができるようになります。
LLMになると言葉遣いなども理解できるようになるため、微妙な言葉の違いにも対応し、よりニュアンスが伝わりやすくなります。結果的にチャットボット相手でも要領を得た言葉が返ってきやすく、満足度も高まりやすくなるのです。
文脈を理解するようになる

例えば、君のことが好きだという言葉には、愛しているという意味もあれば、時に皮肉が込められていることもあります。君のことが好きだを皮肉と捉えるには、やり取りの前後に行われた会話、つまり文脈から感じ取る必要があるのです。
LLMはこうした文脈を理解することもできるようになります。ちょっとした皮肉やジョーク、ダブルミーニングなどは人間だからこそできる芸当でしたが、LLMにもできる時代が訪れようとしています。
LLM(大規模言語モデル)の種類
LLM(大規模言語モデル)にはいくつかの種類があります。ここでは代表的なLLMをまとめました。
GPT系

GPT-1から始まり、GPT-4まで開発されているGPT系はChatGPTを始め、大規模言語モデルのトップランナーともいえる存在です。ChatGPTに代表される質問の応答だけでなく、文章の生成や翻訳なども行います。
3000億語が入っているとされるGPT-3よりもGPT-4はそれよりもはるかに上回っているとされており、文脈の理解など人間同士の会話でしか成立しないことが成立し始めるようになったとされています。
PaLM系
PaLMはGoogleが作り上げた大規模言語モデルです。GPT系に対抗し、対応する言語数を大幅に増やしたことでより精度の高いLLMに仕上げています。PaLMは2023年に続編のPaLM2が出ており、Googleの検索エンジンを始め、Googleのサービスに応用されていくと期待されている状況です。
OpenCALM
英語と比べ日本語は難解であり、英語では使えても日本語では使えないというケースも多々ありました。そんな中、サイバーエージェントが作り出したのがOpenCALMです。日本語を中心に事前学習が行われているほか、商用利用を可能にしたことで、チャットボットへの応用が進むことが予想されています。
LLM(大規模言語モデル)と生成AIとの違い

LLMと生成AIは似ている存在だとされていますが、実は微妙に異なります。LLMの場合はテキストを中心に処理が行われ、テキストが与えられたらそのテキストにふさわしい予測などを行っていきます。
生成AIはテキストに特化しているわけではなく、画像の生成なども行います。いわばLLMはテキストに関する専門ツールであり、生成AIはいくつものジャンルに対応したゼネラリスト的な存在です。このため、LLMで処理したものを生成AIを使って画像を作り上げるという連係プレーも可能になります。
LLMはテキストに特化しているので、より詳しいものを作り出し、より正確なものを生成AIで生み出すのに欠かせない存在となるでしょう。
LLM(大規模言語モデル)の活用事例

LLMの活用事例は多く存在しますが、その中でも代表的な活用事例についてご紹介していきます。
検索エンジン
LLMが強いのは情報検索の分野とされ、たくさんの情報からユーザーが求めることを提案するにはLLMが欠かせません。そのため、検索エンジンのようなサービスはLLMの活用が必須となります。
現在マイクロソフトが提供する「Bing」ではAIチャットが稼働しており、このAIチャットにLLMが使われています。検索エンジンと連携していることから、より正確な情報の提供が行えるようになりました。ただし、Bing自体がGoogleと比べると知名度が低いため、まだまだ知られていません。
AIとの対話
そのGoogleもLLMに力を入れており、Bardという対話型AIを発表しました。人間の会話のようなやり取りが行えることが大きな特徴であり、Googleの検索エンジンとの連携が特徴的です。
就職活動の面接の練習など今まで対人でなければできなかったことが、AIとできるようになる時代が訪れるとされており、今までの状況が大きく変わる可能性もあると言えるでしょう。
LLM(大規模言語モデル)の課題

最後にLLMが持つ課題についていくつかまとめましたのでご紹介します。
ハルシネーションの存在
精度を飛躍的に高めたLLMにおいて、ハルシネーションの存在が課題になりつつあります。ハルシネーションは幻覚を意味する言葉であり、いかにもありがちなウソを意味します。近年話題を集めるChatGPTではよく見られ、特定の人物を紹介してほしいと指令を出したら、事実と異なる情報を組み合わせ、予備知識がない人からすれば本当かのように思ってしまう事態を招きます。
最近ではいかにハルシネーションを起こさないかに力が注がれており、知らない言葉が出てきたら素直に断りを入れるケースも増えてきました。ハルシネーションは混乱を与えかねない要素であるため、開発者も細心の注意を払います。
プロンプトインジェクションの存在
ハルシネーションとはまた別にプロンプトインジェクションの問題も指摘されています。プロンプトインジェクションはLLMを悪用し、非公開にしているプログラムを出させようとする行為です。
また、ChatGPTなどは基本的に中立で特定の立場を示さないように設計されていますが、悪意を持って指示を出すことで特定の立場を示す回答をするようになります。特定の企業が設置したチャットボットで特定の立場を示す回答を出せば、あの企業はおかしな思想を持っているとネット上で騒ぎになってしまいます。こうしたプロンプトインジェクションへの対策も欠かせないため、まだまだ課題はあると言えるでしょう。
言語データの枯渇による大規模化への限界点
大規模言語モデルには大きな可能性があると思われがちですが、実は限界が見えてきたという話もあります。その根拠は言語データの枯渇です。大量の言語データを用いて成長してきたLLMですが、その言語データが数年後には枯渇すると言われています。
枯渇してしまえばLLMの発展は鈍ってしまうのです。今は加速度的な進化を遂げているLLMですが、その進化にも陰りが出てもおかしくない状態にあります。
まとめ
LLMは私たちの生活を劇的に変えられる一方、課題点も多いのがポイントです。特に悪用された時の課題は乗り越えるべきであり、乗り越えられないと人間にとっても何らかの支障が出てくるかもしれません。
AIだからといってプライベートなこと、機密情報などをついつい入力し、それが流出する可能性も十分にあり得るのです。加速度的に進化を続ける分野だからこそ、早急に対応しなければなりません。
さらに、今注目を集める生成AIリスキリングの第一歩を。生成AIパスポートとは?

生成AIパスポートは、一般社団法人生成AI活用普及協会(GUGA)が提供する、AI初心者のために誕生した、生成AIリスクを予防する資格試験です。AIを活用したコンテンツ生成の具体的な方法や事例に加え、企業のコンプライアンスに関わる個人情報保護、著作権侵害、商用利用可否といった注意点などを学ぶことができます。
⽣成AIの台頭により、AIはエンジニアやデータサイエンティストといった技術職の方々だけではなく誰もがAIを使えるようになりました。今、私たちがインターネットを当たり前に活用していることと同様に、誰もが生成AIを当たり前に活用する未来が訪れるでしょう。
そのような社会では、採用や取引の場面で、生成AIを安全に活用できる企業・人材であることが選ばれる前提条件になり「生成AIレベルの証明」が求められることが予測できます。生成AIパスポート試験に合格すると、合格証書が発行されるため、自身が生成AIを安全に活用するためのリテラシーを有する人材であることを、客観的な評価として可視化することが可能です。
ぜひあなたも生成AIレベルを証明し「生成AI人材」に仲間入りしましょう!





